
You may be familiar with the proverb ‘You can lead a horse to water, but you can’t make it drink.’
Thankfully this wisdom doesn’t apply to technical SEO.
You see, you can lead Google’s spider to your website via links and sitemaps.
And, with crawlability and indexability optimisation, you can make it crawl and index your good content (whilst ignoring your thin and duplicate pages).
Technical SEO traditionally referred to optimising your website to be crawled and indexed by search engines. In the modern SEO world, technical SEO includes other factors such as mobile optimisation, Core Web Vitals and schema markup.
In this post, we will focus on the traditional aspects of technical SEO: crawlability and indexability.
Contents
Crawlability vs Indexability
- Crawlability is a search engine bot’s ability to access your website and crawl through your pages.
- Indexability is a search engine bot’s ability to process your content and add it to their search index.
What is Crawlability?
Crawlability is a search engine web crawler’s ability to access your website and crawl through your pages via links. Web crawlers, a.k.a ‘spiders’ or ‘bots’, aim to find and process website content to determine what subjects it covers and whether the search engine should add it to its index.
A web crawler processes more than just the text content. The bots will review internal and external links, sitemaps, various file types, and they will execute code such as HTML and javascript.
The crawler uses this data to determine how your website’s content fits into the broader search environment during the indexing stage.
What does crawlable mean?
Crawlable means a web page allows search engine bots to access and process the content on its pages.
What is Indexability?
The indexability of a website is a measure of how easily a search engine can index the site’s pages and content. An index is a body of data gathered from websites.
Search engines pull results from the index when a user enters a search query.
“Indexing is the process of understanding and storing the content of web pages so that we can show them in the search results appropriately.” – John Mueller, Google.
Why Are Crawlability and Indexability Important?
Optimising the crawlability and indexability of a website is vital in ensuring its pages are returned at the top of Google (and other search engines) when a user enters a search engine query.
A website can’t get traffic from search engines unless its pages are indexed.
If a bot can’t crawl a page, its content can’t be indexed properly.
In allowing the search engine to crawl and understand your content and relate it to queries containing relevant keywords, you can increase the number of search terms your website ranks for and improve your organic search traffic.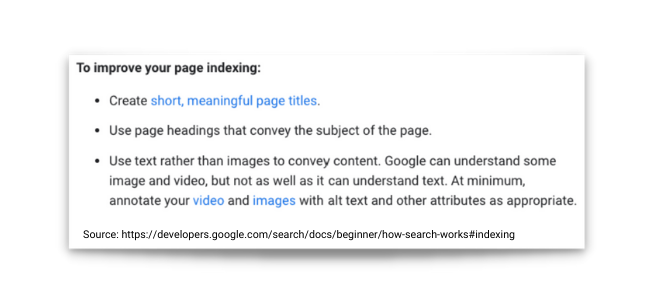
What Issues Affect Crawlability and Indexability?
- Site Structure
- Sitemap.xml
- Duplicate Content
- Crawl Errors
- Internal Linking
- Broken Internal Links
- Broken External Links
- Orphaned Pages
- Internal 301 Redirects
- Broken 301 Redirects
- 302 Redirects
- Redirect Chains
- Redirect Loops
- Page Load Times
- Robots.txt
- Meta Robots Tags
- X-Robots Tags
- Canonical Tags
- Index Bloat
1. Site Structure
Having an organised hierarchical site structure is essential when optimising crawlability.
You must arrange your website’s pages in a way that makes logical sense so bots can flow through your website and establish how sections of your site relate to one another.
Important pages and hubs should be closer to the home page, so Googlebot crawls them more frequently.
2. Sitemap.xml
The sitemap.xml is an XML (Extensible Markup Language) file in the root folder of your domain. The file should contain the URL of every page you want search engines to index and exclude any page you don’t want to be indexed.
You need to submit your sitemap.xml to the search engines. For example, if you want to improve Google’s ability to find your important pages, you can submit your sitemap via Google Search Console.
Giving Google access to your sitemap will act as a roadmap for GoogleBot (Google’s web crawler) and improve your crawlability and indexability.
3. Duplicate Content
Duplicate content is where a URL contains content that is the same as or very similar to another page on the website.
Google confirmed that on-site duplicate content negatively affects your crawl budget, so it is crucial to deal with it appropriately.
Duplicate content is fixed via a 301 redirect, adding original content, adding a canonical link element, or adding an internal link to the original, depending on the cause.
4. Crawl Errors
Crawl errors arise when a web crawler runs into issues, such as server errors when attempting to crawl and index web pages.
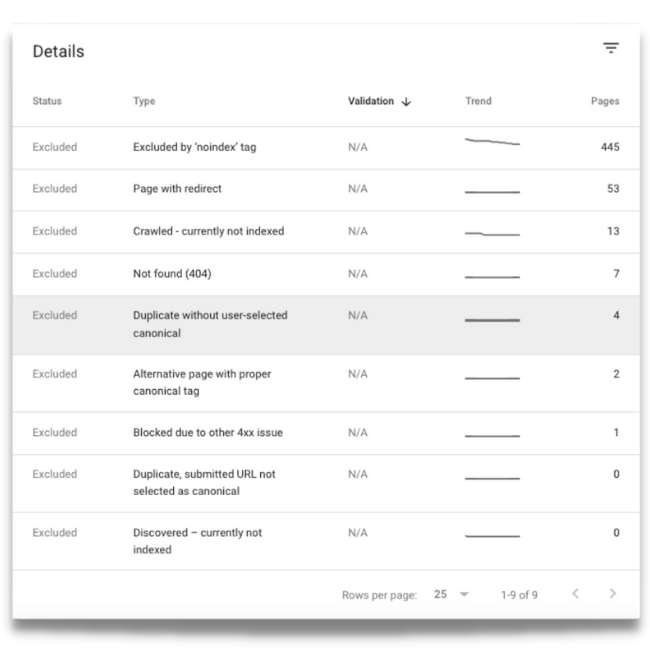
Google shows your website’s crawl errors in the coverage section of Google Search Console, where it splits your pages into four groups:
- Error – pages that couldn’t be indexed.
- Valid with warning – pages that are indexed but may have issues.
- Valid – pages that are indexed.
- Excluded – pages that Google decided not to index.
Each status has various types. Various crawlability and indexability issues will show in each group.
Below is an example type for each status:
- Error: ‘Submitted URL not found (404)’ – a page that no longer exists is still in the sitemap.
- Valid with warning: ‘Indexed, though blocked by robots.txt’ – a page you are blocking in robots.txt has links from another website, so Google ignored the directive and indexed it.
- Valid: ‘Indexed, not submitted in sitemap’- you forgot to include this page in the sitemap, but Google found it anyway.
- Excluded: ‘Duplicate without user-selected canonical’ A page that does not have a canonical URL that Google deemed to be a duplicate of another page.
Given that there can be crawl and index issues under every status, it’s essential to check them all, not just the obvious error and warning statuses.
5. Internal Linking
Internal links are hyperlinks that point from a website page to another page on the same domain. Internal links are how search engine bots navigate your website, the same way humans do.
Internal links are crucial for crawlability and indexability as a page must have inbound internal links to be crawled and indexed.
It is also important that every page on a website links out to at least one other page, so bots don’t hit a dead-end when crawling, and users don’t have to hit the back button and increase your bounce rate.
6. Broken Internal Links
We’ve established that Interlinking the content on your site is great for crawlability. Internal links give web crawlers easy access to the content on your website.
However, broken links that are in this structure will cause a crawler to stop in its tracks. Broken internal links occur when content is removed or moved to another URL, but other pages still link to the old URL.
Broken internal links are a common technical SEO issue we come across when performing SEO audits.
Here’s an example of a website that has 116 broken links, according to Ahref’s Site Audit: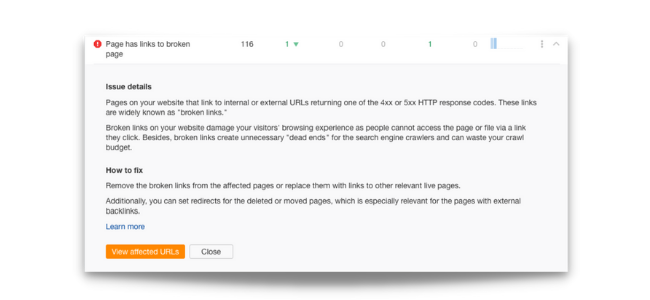
7. Broken External Links
Broken External links are links on your website that point to pages on other websites that no longer exist, another dead-end for Google’s crawler.
Broken external links on your site should be updated to link to a new resource or removed.
8. Orphaned Pages
Orphaned pages are pages on your website that don’t have links from any other pages; they have no ‘parent’ pages.
Orphaned pages exist outside the website’s internal linking structure, which means that users can’t find them.
Search engine web crawlers may still find the page through external links or the sitemap, but they may not index the page if it has no internal links.
Even if Google indexes your orphaned page, the page will not receive any link juice from the rest of your domain, so it is unlikely to rank for any search terms.
9. Internal 301 Redirect
301 redirects are a header response status used when a page has been moved permanently to another URL.
An internal 301 redirect is when a page on your website links internally to a page that has been 301 redirected.
301s add an extra step for web crawlers and is bad crawlability practice. Where possible, you should update the internal link to link directly to the new URL.
10. Broken 301 Redirects
Broken 301 redirects are when an internal link links to a URL that redirects to a page that no longer exists.
If the redirect receives traffic or links from external sources, it should redirect it to another relevant page.
For optimal crawlability, you should update the internal link to link directly to the new page or remove it.
11. 302 Redirects
302 redirects are when a resource is moved temporarily to another URL.
For example, if a product on your site is out of stock, you might redirect the traffic to another page until the product is back in stock.
When auditing indexability and crawlability issues, make sure you check that any 302 redirects are indeed temporary. If the redirect should be permanent, change it to a 301.
12. Redirect Chains
Redirect chains arise when multiple 301 or 302 redirects happen between the starting URL and the final destination.
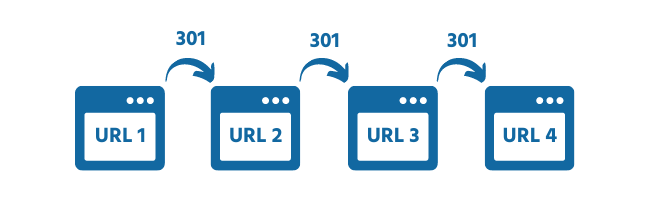 Redirect Chains add extra page load time for users and additional steps for web crawlers. It is, therefore, best crawlability practice to redirect directly to the final destination where possible.
Redirect Chains add extra page load time for users and additional steps for web crawlers. It is, therefore, best crawlability practice to redirect directly to the final destination where possible.
13. Redirect Loops
Redirect Loops arise when the final URL in a redirect chain redirects back to the starting URL, creating an infinite redirect chain.
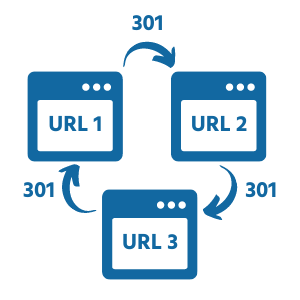
A redirect loop will make users and spiders get stuck, and browsers will show the error message ‘ERR_TOO_MANY_REDIRECTS’.
To fix a redirect loop, you must change the final destination’s header response to ‘200 OK’.
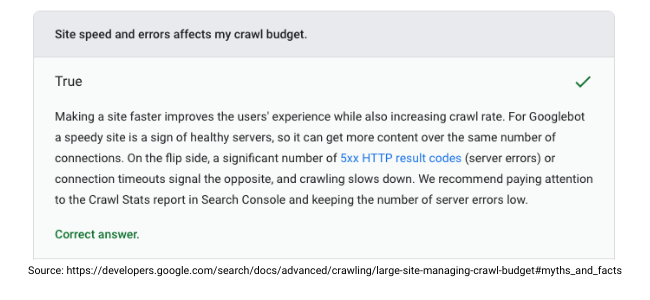
14. Page Load Times
When Googlebot crawls your website, it has to download the resources on your page to the Google servers to be processed.
Search engines will crawl fewer pages if your server response time is slow and your pages are bloated with redundant resources. In other words, slow page load times makes your pages use up more crawl budget.
Optimise your site speed to increase page loading and rendering times for optimal crawling and online visibility.
15. Robots.txt
Robots.txt is a small text file located in your website’s root directory intended for giving instructions to web crawlers.
You can optimise crawlability by using robots.txt to tell spiders where they aren’t allowed to go on your website.
Web crawlers will, by default, crawl any pages they can find on a website. By placing restrictions on what a crawler can access, you can prevent your crawl budget from being wasted on low-value-add, thin and duplicate pages.
You can block bots from crawling specific pages by adding a simple line of text in robots.txt called a disallow directive.
Sometimes web designers leave disallow directives in robots.txt after migration from a staging site by mistake, so always check the robots.txt when performing a technical SEO audit.
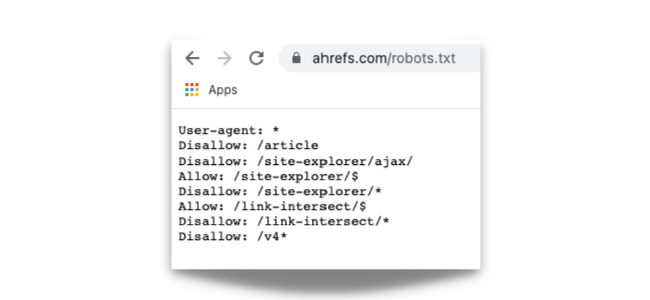
You can check the robots.txt of any website by adding /robots.txt to the end of their domain in your browser.
Here’s an example of Ahrefs.com’s robots.txt:-
16. Meta Robots Tags
Meta tags, also called meta robot directives, are lines of code that web crawlers use as instructions for crawling and indexing a page. Robot meta tags offer more specific instructions than those found in the robots.txt file.
There are several indexation controlling parameters meta robots tags can give as instructions to crawlers. A common mistake is leaving the noindex parameter in the HTML head element when a new or redesigned website goes live.
17. X-Robots Tags
X-robots tags function in the HTTP header of a webpage rather than in the HTML code of the webpage.
Any of the commands that you would give to a crawler using a meta robot tag, you can give as an x-robots tag.
As X-Robots tags do not require html, you can use them to give indexation and crawl instructions to non-html files such as images and pdfs.
18. Canonical Tags
Canonicalization is when a search engine chooses a preferred version of a cluster of duplicate pages.
The search engine will use signals such as internal and external backlinks, redirects, and XML sitemap inclusion to select the best url to represent the cluster in its index – unless you’ve already specified the canonical with a canonical tag.
You should add the rel=canonical tag to every page, including a self-referential canonical tag on the master pages. Advising search engine crawlers whether the page is canonical or non-canonical will allow them to process and index more efficiently.

19. Index Bloat
Index bloat occurs when Google includes low-value-add content from your site in its index.
When Google crawls and indexes thin, duplicate and paginated content from your website, it uses up precious crawl budget.
Common culprits of index bloat are tag pages, media attachments, non-https versions, having both non-www and www indexable, pagination, and url parameters.
When Googlebot has to navigate hundreds or even thousands of these low-quality pages to find pages with good content, it lowers the perceived quality of your website.
You can use disallow, nofollow, and noindex directives and canonical tags to clean up index bloat.
Why perform a crawling and indexing audit?
Performing an audit on crawlability and indexability factors can make or break your SEO campaigns.
If Google can’t crawl or index your pages correctly, all of your content creation and link building efforts are in vain.
We recommend that you check crawlability and indexability issues every three months and every time you make significant changes to your website.
If you’re an agency trying to land SEO clients, showing the lead how Google can’t crawl or index one of their primary pages can be a very effective strategy.
Tools such as Screaming Frog or the site audit feature of Ahrefs make detecting most of these crawling and indexing issues simple and free. Get it done. You have no excuse!